Les billets de Thierry Bur n°10 – 2ème partie : Stocks de sécurité dans la supply chain : quel dimensionnement ?
 Nous avons vu dans le billet précédent que la formule relative au calcul du stock de sécurité est certes simple, mais n’est pas en lien direct avec le taux de service effectif, car ce dernier dépend notamment de la variabilité de la demande, de la variabilité du délai de livraison et de la fréquence effective d’approvisionnement. Bref, cette formule de dimensionnement des stocks est-elle à rejeter, ne fait-elle plus sens aujourd’hui ? Quelles sont les autres bonnes pratiques de gestion des stocks ?
Nous avons vu dans le billet précédent que la formule relative au calcul du stock de sécurité est certes simple, mais n’est pas en lien direct avec le taux de service effectif, car ce dernier dépend notamment de la variabilité de la demande, de la variabilité du délai de livraison et de la fréquence effective d’approvisionnement. Bref, cette formule de dimensionnement des stocks est-elle à rejeter, ne fait-elle plus sens aujourd’hui ? Quelles sont les autres bonnes pratiques de gestion des stocks ?
Comment les nouvelles méthodes d’analyse des données, la data sciencea, peuvent-elles contribuer à améliorer la qualité de service et le dimensionnement des stocks ?
Partie 2 : Dimensionnement pertinent du stock de sécurité
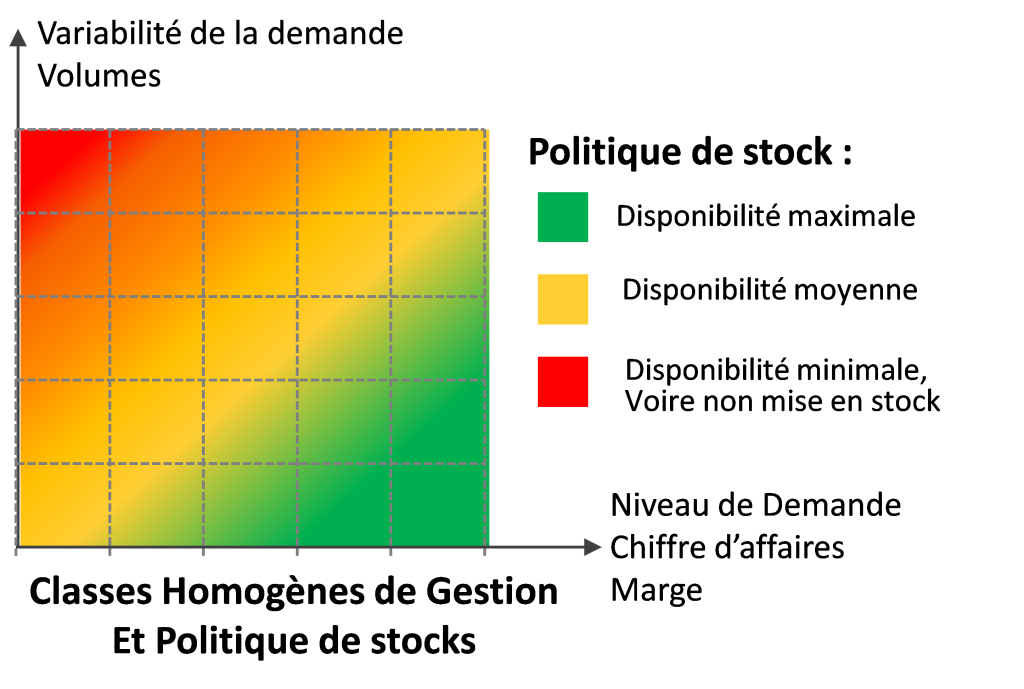
1. Politique de stock et Classes Homogènes de Gestion
Les articles stockés ou susceptibles d’être stockés sont généralement très nombreux.
Or, compte-tenu des ressources limitées de l’entreprise (trésorerie, surfaces de stockage…) et de ses exigences de rentabilité du capital investi –et le stock peut être considéré comme tel-, il faudra établir quels sont les stocks à constituer qui permettront au mieux de contribuer aux objectifs de l’entreprise : taux de disponibilité, marge, chiffre d’affaires.
Ceci est traduit au travers d’une politique de stockage qui consiste à établir quels sont les articles qui doivent être stockés, le niveau de service associé, leur fréquence d’approvisionnement. Cette politique de stockage ne peut pas être définie pour chacune des références, ce qui serait totalement illisible et incompréhensible.
Aussi, crée-t-on une catégorie intermédiaire de regroupement des articles, les Classes Homogènes de Gestion regroupant des articles similaires en termes de critères de gestion des stocks.
Les critères pour définir une classe homogène de gestion sont par exemple :
- Une segmentation des articles selon l’acuité des attentes des clients, selon l’intensité de la concurrence…
- Une classification selon les données représentatives de l’objectif poursuivi : Chiffre d’affaires, Marge, Nombre de demandes ou de lignes de commandes
- Une classification selon les contraintes de stockage (Volumes, Poids, coût unitaire)
- D’autres caractéristiques d’approvisionnement : importance et régularité de la demande, fréquence d’approvisionnement, délais d’approvisionnement…
La politique de stockage se traduit généralement par une différenciation des objectifs :
- Un objectif de disponibilité d’autant plus important que les articles sont importants pour l’objectif poursuivi (par exemple, marges ou chiffre d’affaires les plus importants possibles),
- Un objectif de disponibilité d’autant moins important que les articles présentent davantage de contraintes (par exemple : variabilité de la demande, volume ou poids, voire coût unitaire…)
 2. Modélisation des aléas
2. Modélisation des aléas
2.1 Autre formule généralisée pour le stock de sécurité
On trouve dans la littératureb quelques autres formules et en particulier![]()
correspond à l’écart-type du délai (Sigma Demande), à l’écart-type de la demande et Délai Moyen correspond au délai moyen d’approvisionnement et non le délai théorique.
Cette formule présente un avantage : elle intègre les aléas relatifs au délai de livraison.
Elle présente en revanche deux natures d’inconvénients :
- En premier lieu, les inconvénients liés à la formule simplifiée qui ne concerne que les aléas de la demande, à savoir la difficulté à établir le lien entre le taux de service et le coefficient de sécurité
- En second lieu, elle ne définit pas comment calculer l’écart-type du délai ! Elle est donc théorique et je doute des résultats de l’application d’une telle formule !
Et enfin, la distribution statistique du délai de livraison n’est pas symétrique :
- Les fournisseurs livrent rarement en moins de temps que le délai théorique
- En revanche, différents aléas peuvent conduire à des retards plus ou moins longs
A titre d’illustration, vous trouverez ci-dessous une répartition des délais de livraison :
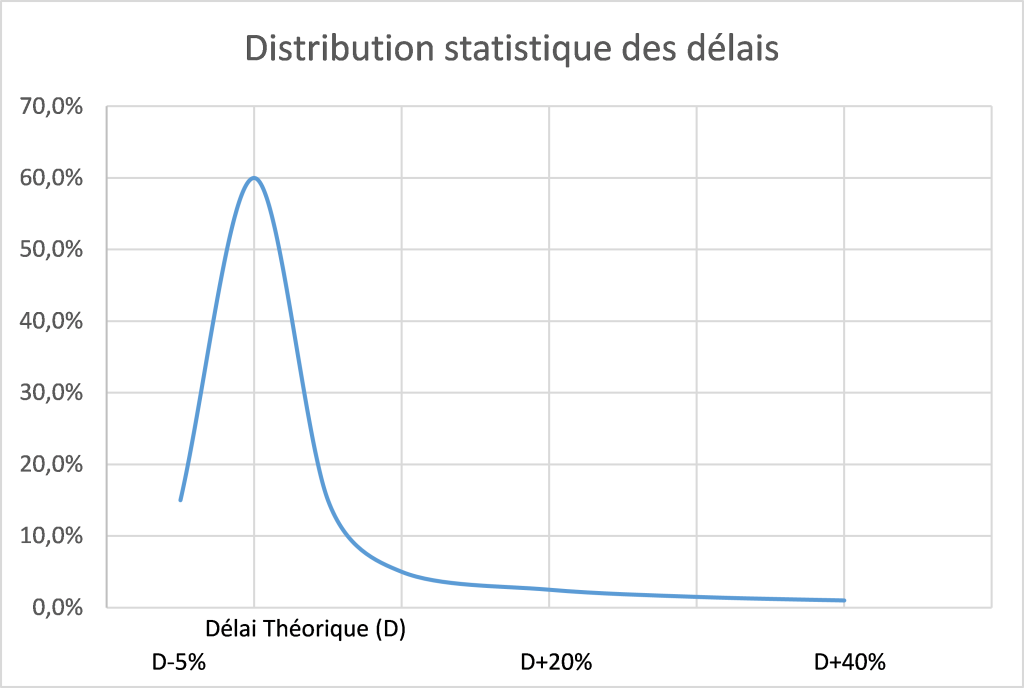
Dans le cas de l’illustration ci-dessus, l’écart-type du délai n’est que de 0,10 x Délai Théorique et l’impact de cette donnée est faible sur la formule précédente.
Ainsi, l’application de la formule précédente en considérant ID=20% et DélaiMoyen = 1,025 DélaiThéorique conduirait à une majoration de 20% du stock de sécurité seulement. Cet ajustement du stock de sécurité permet de maintenir à peu près le même taux de service que dans le cas où le délai de livraison était strictement respecté.
Cependant, comme dans le cas plus simple des délais strictement respectés, elle ne donne aucune indication quant au taux de service effectivement atteint :
- Un coefficient de sécurité de 1,3, associé à une probabilité de 9,7% peut conduire à taux de rupture de 1%,
- Un coefficient de sécurité de 2, associé à une probabilité de 2,3% peut conduire à taux de rupture de 0,3%.
2.2 Variabilité du délai de livraison
2.2.1. Comment mesurer la variabilité du délai de livraison
Doit-on établir la variabilité du délai de livraison sur la base des données d’approvisionnement de chaque référence ?
Cela revient à considérer que la variation du délai constatée sur une référence au cours des derniers mois ou dernières années. Ceci consiste à estimer que la qualité de sa prestation passée du fournisseur sur une référence donnée est extrapolable sur les semaines à venir.
Ceci est contestable, surtout si le nombre d’approvisionnements a été limité : dans l’exemple précédent, seuls 5% des approvisionnements présentent un retard significatif, pourtant ce dernier est très structurant.
L’avantage de cette approche est d’identifier les retards fréquents de livraison, signe d’une problématique propre à cette référence (difficulté d’approvisionnement ou mauvais paramètrage du délai d’approvisionnement)
Doit-on établir cette variabilité du délai de livraison au niveau fournisseur (ou site fournisseur), sur la base des données d’approvisionnement de l’ensemble de ses références ?
Cette approche semble a priori plus pertinente, notamment parce que les processus de fabrication et de planification conditionnent globalement la performance de production, notamment en termes de respect des dates de production (On Time Delivery). Il en est de même pour les opérations de transport qui sont généralement un processus commun pour l’ensemble des livraisons d’un site fournisseur.
La réalité est cependant un peu plus complexe, et la performance peut dépendre de plusieurs facteurs :
- La performance intrinsèque du fournisseur,
- Les caractéristiques de l’article, en particularité la régularité des approvisionnements et la variabilité de la demande,
- Plus rarement, des spécificités liées au processus industriel propre à un ou quelques articles qui les rendent plus difficiles à produire que les autres
En dehors du dernier facteur, l’ensemble des données sont disponibles chez le client pour mener à bien une analyse de la performance du fournisseur, notamment en tenant compte des caractéristiques des articles.
Ces différents facteurs sont décrits dans le tableau suivant :
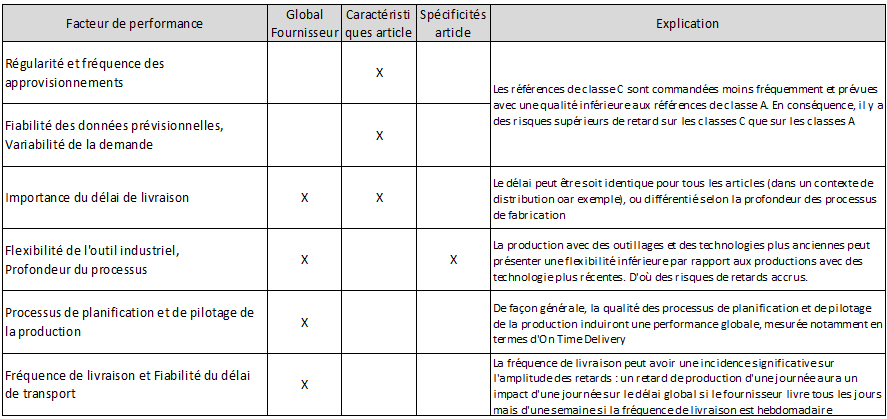
Influence de différents facteurs sur le respect des délais de livraison
L’analyse des retards peut conduire à des modélisations différentes selon les environnements :
- L’amplitude des retards est souvent différenciée selon les classes homogènes de gestion,
- L’amplitude du retard est proportionnellement plus réduite sur des délais longs,
- La plupart des fournisseurs ont des performances comparables, permettant de dimensionner stock de sécurité tenant compte de cette performance moyenne. Le stock de sécurité peut en revanche être diminué sur les fournisseurs excellents ;
2.2.2. Doit-on positionner un stock de sécurité pour compenser la variabilité du délai ?
Deux réponses a priori contradictoires fusent généralement :
- On ne peut pas accepter les retards,
- Il faut prendre en compte la réalité pour dimensionner le stock de sécurité et garantir à nos clients la qualité qu’ils attendent.
L’attitude consistant à nier l’existence des retards n’est pas constructive, car elle consiste à nier une réalité effective (dont le client demandeur du stock n’est peut-être pas exempt de toute responsabilité) et surtout à exiger unilatéralement une amélioration de la performance du fournisseur.
L’attitude pertinente consiste à :
- Mesurer l’amplitude de la variabilité des délais fournisseurs et intégrer dans dimensionnement des stocks de sécurité cette variabilité, tout en mesurant le stock qu’il représente,
- En parallèle, de mener des actions pour réduire cette variabilité.
Diverses actions sont susceptibles de permettre d’améliorer la performance du fournisseur, en particulier au travers d’une intensité de la relation client-fournisseur plus fortec :
- La première étape consiste à connaître de façon plus précise les processus, les modes de fonctionnement et les contraintes opérationnelles de part et d’autre. Des paramètrages plus fin et de premières pistes d’amélioration peuvent ainsi être établis,
- Le niveau d’exigence et de pression mis sur le fournisseur, accompagné d’une supervision systématique et fréquente doit aussi permettre de le conduire à s’améliorer,
- Enfin, la mise en œuvre de modes de fonctionnement collaboratifs plus efficients permettra également d’améliorer globalement la performance et de réduite la variabilité fournisseur. Nous y reviendrons dans le troisième billet consacré au dimensionnement des stocks de sécurité.
2.3 Modélisation des aléas et du taux de service
Nous développons ci-dessous les principes qui nous permettent d’établir le taux de service en fonction d’un niveau de stock de sécurité donné.
Pour ce faire, nous nous appuyons sur trois éléments :
- La formule usuelle
![]()
- Une modélisation des retards de livraison,
- Une méthodologie pour évaluer le taux de service effectif en fonction d’un niveau de stock de sécurité donné, déjà évoquée dans le premier billet.
La mise en œuvre de cette méthode pour déterminer le taux de service est illustrée par les deux exemples ci-après.
Sur une référence avec une demande régulière
![]()
un coefficient de sécurité k de 1,6 permettrait d’atteindre un taux de service de 99,3% en l’absence de tout retard et conduit à un taux de service de 96,5% en tenant compte des retards potentiels. La prise en compte d’un coefficient de 2,8 permet dans ce cas d’atteindre le taux de service effectif de 99,3%. Il faut de ce fait majorer le coefficient k initial d’un facteur multiplicateur de 1,75 pour tenir compte des retards potentiels.
Sur une référence avec une demande plus irrégulière (ID = 40%), un coefficient de sécurité k de 1,3 devrait permettre d’atteindre une qualité de service jugée satisfaisant de 97,5%, en l’absence de tout retard de livraison. Ce coefficient conduit cependant à une qualité de service de 95,5% du fait des retards de livraison. Il faut dans ce cas passer à un coefficient de 1,63 pour atteindre le taux de service effectif de 97,5%. Il faut de ce fait majorer le coefficient k d’un facteur multiplicateur de 1,25 pour tenir compte des retards potentiels.
En synthèse, il est possible d’appliquer des coefficients correctifs pour atteindre une qualité de service donnée en tenant compte de la réalité des retards possibles. Ce coefficient de correction est cependant variable, il dépend en particulier :
- De la régularité de la demande (ID) : le coefficient de correction sera d’autant plus élevé que la demande est régulière,
- Du taux de service visé (le coefficient appliqué sera d’autant plus faible que la valeur initiale de k est élevée).
3. Applicabilité de la formule du stock de sécurité
Ainsi donc, nous avons démontré que l’utilisation de la formule classique de dimensionnement des stocks de sécurité continue de faire sens, malgré ses nombreuses limites… mais à condition de procéder à des modélisations complémentaires.
Plutôt que d’évaluer les valeurs du coefficient de sécurité k de façon empirique, je recommande une détermination plus précise de cette valeur en tenant compte :
- D’une évaluation des retards de livraison,
- D’une modélisation des cycles d’approvisionnement pour évaluer le taux de service (et non des probabilités de rupture)
- Des différentes classes homogènes de gestion sur lesquelles les modélisations précédentes seront réalisées.
Ce type de modélisation, que j’ai mise en œuvre dans différents environnement de distribution, a permis d’optimiser à la fois les stocks et la qualité de service, en mettant en œuvre une politique de stock plus pertinente et souvent plus tranchée. Au-delà de la mise en œuvre de l’approche précédente, d’autres optimisations peuvent être mise en œuvre de façon complémentaire, par exemple en termes d’approfondissement des relations avec les fournisseurs mais aussi au travers de l’optimisation des quantités d’approvisionnement.
Bien sûr, la condition majeure de la mise en œuvre de travaux de cette nature est la connaissance de la demande et de sa variabilité effective, ainsi que la mesure de la variabilité du délai de livraison.
4. Autres façons de formuler le stock de sécurité
Dans d’autres environnements, le stock de sécurité est exprimé en nombre de jours ou de semaines de stock, ce qui est particulièrement pertinent lorsque les aléas de livraison sont supérieurs aux aléas de demande.
Le même type d’approche d’optimisation du dimensionnement du stock de sécurité que celle décrite précédemment peut être mis en œuvre dans ce cas.
Enfin, dans des contextes de demande très faible, par exemple avec des pièces de rechange, des modélisations sont là aussi possibles et permettent de dimensionner précisément le stock sur les diverses références : il s’agit dans ce cas d’une simulation référence par référence pour déterminer le taux de service permis par la mise en stock d’une pièce (98,7% par exemple), de deux pièces (99,9%) ou plus puis de décider de la quantité à stocker compte tenu de la politique de stock définie.
Des modélisations plus fines encore sont possibles, qui permettent :
- L’évaluation du lien entre le taux de disponibilité des pièces de rechange et le taux de disponibilité de l’équipement associé
- De positionner des stocks, par exemple à budget fixe, en favorisant la mise en stock d’une pièce en plus selon le critère de la rentabilité en terme d’amélioration de la disponibilité en fonction du coût unitaire de la pièce.
5. Data Science et stocks de sécurité
A l’heure où tout le monde parle de big data dans la supply chain, nous avons au travers des préconisations précédentes une illustration concrète d’un cas d’emploi de la data science au service de l’aide à la décision.
Cette approche de « data science » appliquée aux stocks impliquera :
- Une collecte des données de stocks, de demande et d’approvisionnement selon une fréquence élevée (constitution d’historiques journaliers voire horaires) et avec une grande finesse (distinction des différents compteurs de stock, des types de demande…)
- Des outils d’analyse capables d’identifier et de modéliser des phénomènes tels que des retards fournisseurs, en identifiant les populations sur lesquelles les phénomènes ont un comportement homogènes,
- Des hommes capables d’analyser les données précédentes et de les interpréter de façon pertinente, puis de mettre en œuvre les actions adéquates :
- Actions correctives immédiates : par exemple des changements de paramètres inadéquats,
- Actions d’améliorations : par exemple des plans d’amélioration de la performance fournisseur,
- Actions de neutralisation des aléas : dimensionnement des stocks de sécurité selon la politique de stock poursuivie et selon les aléas identifiés.
Cette approche est-elle révolutionnaire ?
Les modélisations décrites dans le cadre de ce billet existent depuis plusieurs décennies et n’ont donc rien de révolutionnaire du point de vue théorique. Cependant la mise en œuvre de cette approche est aujourd’hui peu répandue du fait :
- De l’absence de connaissance de ce type d’approches et quelquefois d’une confiance limitée dans les approches de modélisation statistique,
- Du niveau d’expertise requis pour l’analyse des données et la modélisation, qui est assez peu répandue,
- Dans certains cas, de l’absence de données suffisamment fines pour mener ces analyses,
- De la lourdeur de l’analyse de ces données avec des outils actuels de BI
Aussi, des démarches de type data science pourront-elles faciliter la mise en œuvre de ce type d’optimisation des stocks, en facilitant la collecte des données, les analyses et leur exploitation pour mener à bien les travaux.
Si révolution il y a, elle résidera dans l’ampleur du déploiement de ce type d’approche.
De plus, l’application de la data science ira bien au-delà de l’optimisation du dimensionnement des stocks de sécurité. Nous aurons l’occasion d’y revenir dans le cadre d’un nouveau billet qui sera dédié à la data science dans la gestion de la chaîne logistique.
6. Conclusion
La formule classique de dimensionnement des stocks de sécurité est simple mais difficile à connecter avec le taux de service effectif des références auxquelles elle s’applique. En effectuant un contresens, certains considèrent que le coefficient de sécurité k donne en lecture directe la qualité de service associée aux articles, alors qu’il ne s’agit que d’une probabilité de tomber en rupture sur un cycle de réapprovisionnement, et encore, en supposant que le fournisseur respecte toujours le délai de livraison théorique.
Dans le cadre de ce billet, nous avons démontré ici la possibilité, au travers de modélisations complémentaires, de dimensionner le stock de sécurité de façon plus pertinente, en pouvant faire le lien entre le niveau de stock de sécurité et le taux de service effectif. Combiné avec une définition claire de la politique de stock, ce type d’approche permet d’accroître la rentabilité du stock du point de vue économique ou du point de vue de la qualité de service.
Les nouveaux outils de la data science devront permettre de systématiser ces approches de dimensionnement des stocks en les rendant plus accessibles. Nous y reviendrons dans le cadre d’un billet dédié à ce sujet.
Nous évoquerons, dans le troisième billet consacré au stock de sécurité, d’autres leviers complémentaires pour l’optimisation des stocks.
Auteur : Thierry Bur
Notes :
a La data science ou science des données s’occupe de collecter les données, d’en faire des statistiques, de vérifier leur valeur, de les structurer, de les organiser et d’en élaborer la visualisation.
Le défi de la science des données est de jouer avec des données qui sont à la fois gigantesques, hétérogènes, peu fiables, et souvent lacunaires. http://gdt.oqlf.gouv.qc.ca/ficheOqlf.aspx?Id_Fiche=26527074
Ce terme est plus approprié que « big data » qui est plus vague (définition : Ensemble des données produites en temps réel et en continu, structurées ou non, et dont la croissance est exponentielle).
b https://fr.wikipedia.org/wiki/Stock_de_s%C3%A9curit%C3%A9
c Pour aller plus loin, Jeffrey K Liker et Thomas Y Choi ont décrypté les bonnes pratiques de Toyota et Honda dans leurs relations avec les fournisseurs dans Building Deep Supplier Relationships, synthétisées dans le billet http://blog.cereza.fr/logistique-scm/les-billets-de-thierry-bur-n4-lean-et-supply-chain-management-6eme-partie-les-implications-du-lean-dans-la-suppply-chain-1032

Envoyer un commentaire
Rejoignez la discussion ?contribuez!